Utilização de LLMs para a tarefa de classificação de textos com múltiplas intenções
Análise realizada através de embeddings gerados pelos modelos BERT, LLAMA 2 e GPT4 como entrada para uma rede neural convolucional.

A tarefa de classificação de texto é um processo de atribuição de categorias em sentenças com base em seu conteúdo, permitindo que muitos sistemas inteligentes se beneficiem através de tarefas como análise de sentimentos, sistemas de recomendações, filtragem de span e no uso em chatbots no reconhecimento de intenções.
A automação da classificação de texto pode auxiliar a industria a personalizar serviços, minimizando custos em atendimento, agilizando processos e melhorar a experiencias no atendimento. Todos esses cenários são amplificados pela evolução constante do PLN, abrindo novos horizontes para aplicações cada vez mais poderosas.
Com a expansão dos dominios de aplicações de PLN e a vasta quantidade de opções metodológicas, surgem diversos desafios na busca de escolher o melhor método para resolver um determinado problema. Nesse cenário podemos citar problemas comuns encontrados em tarefas de classificação de texto, como: base de dados com diferentes intenções e dominios, diversidade de idiomas, evolução da linguagem com o tempo, desbalanceamento de classes, entre outros. Para enfrentar esses desafios, profissionais recorrem a uma variedade de estratégias, incluindo o desenvolvimento de novos algoritmos, técnicas de processamento especializados ou até mesmo abordagens de aprendizado por transferência.
Esse estudo busca resolver o problema de classificação de texto em cenários de múltiplas intenções utilizando representações vetorias geradas pelos modelos GPT4, LLMA 2 e BERT como uma tarefa de pré-processamento. Uma vez realizada o processo de representação vetorial, é utilizada uma rede convolucional com três camadas de convolução para buscar padrões entre os embeddings. Como resultado, comparamos a eficácia dos embeddings gerados pelos três modelos e analisamos o resultado na busca da identificação de uma intenção dado uma nova sentença.
Revisão da Literatura
O advento dos LLMs tem revolucionado o campo PLN ao proporcionar representações ricas e contextualizadas de textos e sentenças após serem treinadas em grandes conjuntos de dados, aprendendo nuances linguísticas e possibilitando a geração de representações de dados em um espaço com N dimensões, conhecidos como embeddings.
A geração de embedding é uma técnica muito útil para lidar com dados categóricos e textuais em tarefas de aprendizado de máquina. Antes de toda revolução gerada pela arquitetura transformers, a geração de embeddings já eram amplamente utilizadas no contexto de PLN, sendo as mais notaveis, técnica de Word2Vec, Glove e FastText.
A diferença de qualidade entre esses métodos de geração de embedding e os novos se deu pela evolução de arquitetura. A arquitetura Word2Vec, por exemplo, gera representações vetoriais fixas para cada palavra, não levando em conta a polissemia (quando uma palavra pode ter significados diferentes em contextos diferentes). Já a arquitetura dos modelos mais recentes, chamada de transformes, possibilita uma compreensão de texto muito melhor, não somente levando em consideração a polissemia na geração de embedding mas também pelo poder de gerar representações especificas para cada palavra em uma determinada sentença.
Através da arquitetura transformers, surgiram propostas para diferentes abordagens, como o caso dos modelos BERT, GPT e LLMA. Os transformers são uma arquitetura de modelo introduzido no artigo “Attention is All You Need” por Vaswani em 2017, projetado para lidar com sequências de dados, como texto, superando limitações de abordagens anteriores baseadas em Redes Neurais Recorrentes (RNNs). A partir de então, variações dessa arquitetura começaram a aparecer, entre elas o BERT, GPT e LLMA.
O modelo “Bidirecional Encoder Representations from Transformers” (BERT), é um modelo desenvolvido por pesquisadores do Google no ano de 2018 com a capacidade de processar tokens de texto de forma bidirecional, ou seja, considerando simultaneamente o contexto à esquerda e à direita de cada token em uma sequência.
O modelo “Generative Pre-trained Transformer” (GPT), se trata de uma série de modelos desenvolvidos pela OpenAI para geração e compreensão de textos. Diferentemente do BERT, que utiliza a arquitetura transformer em um contexto bidirecional, o GPT é treinado como um modelo autoregressivo, o que significa que ele gera texto prevendo a próxima palavra da sequência, dada uma sequência de palavras anteriores, permitindo que o modelo gere texto coerente e contextualmente relevantes.
Embora detalhes específicos sobre a arquitetura do “Large Language Model Meta AI” (LLaMA) possam não ser amplamente divulgados, ele segue a mesma proposta dos modelos já mencionados, treinado de forma mais abrangente, visando não somente a compreensão do texto. O que caracteriza o LLaMa é sua versatilidade lidando com o melhor dos modelos BERT e GPT, sendo adequado para uma variedade de tarefas de PLN, adaptável a diferentes tarefas de PLN com ajustes minimos.
Tendo em vista o poder dos embeddings gerados pelos modelos mencionados, com base na representação vetorial que podemos atingir dado a quantidade de material utilizado pelo estudo, o seu uso pode ser muito poderoso para a tarefa de classificação. Porem dado a quantidade de características geradas, esses vetores tendem a ter grandes dimensões, podendo ter um alto poder computacional na identificação de padrões. Dado esse cenário, podemos fazer uma correlação com treinamento de imagens, que também possuem matrizes com mais de uma dimensões, abrindo assim uma oportunidade de utilização de uma arquitetura que tem sido até então um das melhores para processamento de imagens, ás redes neurais convolucionais (CNN).
Originalmente projetadas para estudos no campo de visão computacional, os modelos convolucionais se mostraram posteriormente eficazes para a PLN e alcançaram bons resultados em análise semântica, recuperação de consultas em motores de busca e outras tarefas tradicionais de PLN. Ao contrario dos modelos de visão computacional tradicionais que empregam pixels de imagem como entradas para uma CNN, a maioria dos modelos desenvolvidos para tarefas de pré-processamento de PLN utiliza sentenças ou documentos textuais representados como matrizes numéricas. Nessa abordagem, a CNN alimentada com matrizes, nas quais cada linha pode corresponder a um conjunto de token á representar uma sentença. O trabalho de KIM (2014) avalia uma arquitetura CNN em diversos conjuntos de dados destinados a classificação. Esse conjunto de dados abrangem predominantemente tarefas de análise de sentimentos e reconhecimento de intenções. Conforme apresentado na FIGURA, a camada de entrada é uma frase composta por embeddings que são concatenados para formar uma sentenã. Em seguida, a arquitetura envolve camadas convolucionais, equipadas com filtros que visam calcular o contexto e a similaridade entre os tokens. A sequência de camadas processegue com uma cada de pooling, que resuzem a dimensionalidade gerada pelos filtors. Por fim, o processo culmina em um classificador que gera uma saída correspondente à intenção ou sentimento associado à sentença em análise.
Metodologia
Dados
Para a comparação foi utilizado a base de dados ATIS (Airlin Travel Information System), base de dados amplamente utilizada no campo da PLN, especialmente em tarefas relacionadas à compreensão e classificação de texto. Originária de um esforço colaborativo no início dos anos 90, a ATIS foi criada para facilitar o desenvolvimento e a avaliação de sistemas de diálogo inteligente voltados para informações de viagens aéreas. A base de dados contém transcrições de áudio de consultas feitas por usuários a um sistema de informações de viagens aéreas, juntamente com anotações correspondentes em textos incluido perguntas sobre voos, tarifas, horários, conexões, reservas de bilhetes, entre outros assuntos relacionados a viagens aéreas.
Pré-processamento
Todas as sentenças contidas na base de dados passaram por um processo de Word Embedding utilizando os modelos BERT, GPT-4 e LLAMA2. Para os modelos BERT e LLAMA2 essa tarefa foi possivel através da biblioteca SenteceTransformer. Já para o modelo GPT4 foi utilizado a própria API disponibilizada pela OpenAI através de seu modelo de embedding “text-embedding-3-small”. Cada modelo possui sua propria quantidade de características, sendo:
- BERT: 768 dimensões (bert-base-uncased).
- GPT4: 1536 dimensões (text-embedding-3-small).
- LLMA2: 4096 dimensões (meta-llama/Llama-2–7b-hf).
Treinamento da CNN
Após gerados os embeddings, todos os modelos passaram por um processo de otimização de hiperparâmetros utilizando validação cruzada com a estratégia de Busca aleatória através de uma distribuição pré estabelecida entre 128, 256 e 512 filtros convolucionais e 512, 1024 e 2048 neurônios na camada densa. Após esse processo, obteve-se:
- BERT: 256 filtros e 1024 neurônios.
- GPT4: 256 filtros e 512 neurônios.
- LLMA2: 128 filtros e 512 neurônios.
Com os parâmetros estabelecidos, a rede convolucional recebeu os embeddings de cada modelo possuindo as seguintes caracteristicas:
- Camadas de Convolução: o modelo é composto por 3 camadas de convolução de uma dimensão formadas de 2, 3 e 4 kernels. As camadas de convolução foram treinadas cada uma com uma quantidade de filtros entre 128, 256 e 512 filtros utilizando a função de ativação relu;
- Camada Max Pooling: Camada de 1 dimensão responsável por resgatar o valor de cada filtro gerado pelas camadas de convolução;
- Camada Densa: Camada composta por 512, 1024 ou 2048 neurônios que recebem os resultados concatenados da camada de max pooling e aplica a função de ativa ção relu;
- Camada de Dropout: Camada para prevenir overfitting configurado com o intuito de regularizar 10% dos neurônios;
- Camada Densa de Saída: Camada de saída do modelo composta por 22 neurônios que utilizam a função de ativação softmax retornando uma probabilidade para cada uma das classes;
Resultados
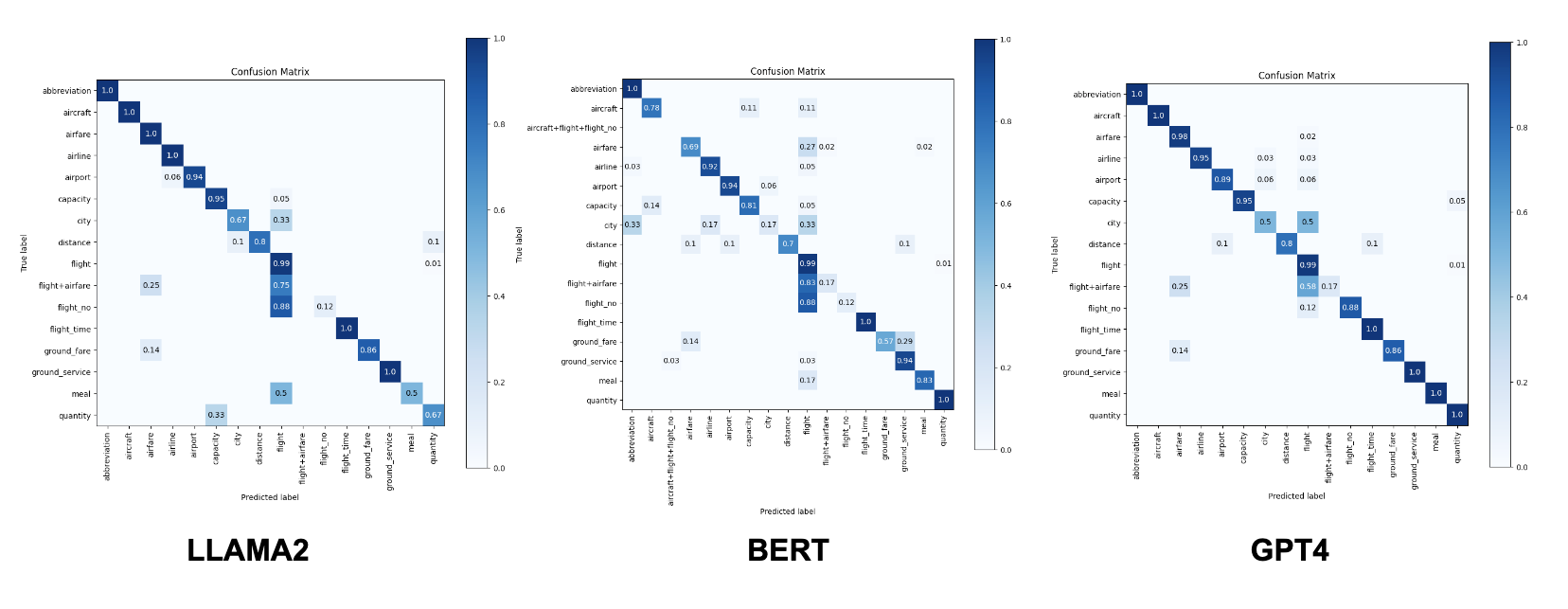
Segue os resultados obtidos nos diferentes treinamentos do modelo CNN avaliando diferentes métodos de incorporações de palavras de multiplas dimensões. O modelo foi treinado por 20 épocas, também utilizando validação cruzada.
- LLAMA2: 0.96% de acurácia;
- GPT4: 0.93% de acurácia;
- BERT: 0.93% de acurácia;
Conclusão e discussões
Entre os modelos de incorporação investigados, o modelo LLAMA2 destacou-se como a abordagem mais interessante para classificação de intenções. Isso pode ser justificado pelo tamanho do vetor de características gerados pelo modelo em comparação com os outros. Deve-se levar em consideração também a quantidade de dados e o contexto que o modelo foi desenvolvido.



